下载与安装Hadoop
前往官网下载Hadoop 3.3.1压缩包,页面如下:
点击tar.gz文件,等待下载结束。
下载结束后,开启Terminal,前往Hadoop压缩包的存储目录,并将其解压到指定目录下(目录可以换,且可以手动复制)。命令如下:
cd ~/Downloads
tar -zxf hadoop-3.3.1.tar.gz -C /usr/local/Cellar 然后进入解压目录,将文件名重命名为hadoop。
cd /usr/local/Cellar
mv hadoop-3.3.1 hadoop配置Mac OS环境变量
为了方便执行hadoop程序,可以通过编辑~/.bash_profile文件为hadoop添加环境变量。使用Mac自带的vim编辑器修改文件:
vim ~/.bash_profile 在文件最后添加如下内容(直接复制粘贴即可,需要注意HADOOP_HOME的值为hadoop的实际存储根目录):
export HADOOP_HOME=/usr/local/Cellar/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin配置Hadoop
Hadoop的配置总共需要修改四个文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml。
首先前往这四个配置文件的存放目录:
# 当前目录为Hadoop根目录
cd etc/hadoop 然后通过vim编辑器修改上述四个文件的<configuration>如下:
core-site.xml:其中hadoop.tmp.dir必须是实际存在的目录,如果不存在则需要自己创建。hadoop.proxyuser.Ray.hosts中的Ray则是计算机登陆账户的用户名。hadoop.proxyuser.Ray.groups同理,自行修改。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/Cellar/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.Ray.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.Ray.groups</name>
<value>*</value>
</property>
</configuration>hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/Cellar/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/Cellar/hadoop/tmp/dfs/data</value>
</property>
</configuration>yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>设置免密登录
首先测试是否能够通过SSH免密登陆本机。
ssh localhost如果不能,依次执行如下三条命令设置免密登陆:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys格式化HDFS文件系统
在确保完成以上步骤后,可以格式化HDFS文件系统:
如果已经配置了环境变量:在任意目录下执行如下命令即可
hdfs namenode -format如果没有配置环境变量:首先需要进入
hadoop/bin目录,然后执行上述命令即可格式化成功后,能够在
Terminal打印输出中查找到successfully formatted字样。
开启与关闭Hadoop集群
通过以上步骤,便已经完成了Mac下Hadoop 3.3.1的安装与配置。
下面开启Hadoop集群:
如果已经配置了环境变量:在任意目录下执行如下命令即可
# 方法一:依次开启hdfs和yarn start-dfs.sh start-yarn.sh # 方法二:同时开启hdfs和yarn,此方法在配置了Spark环境变量后会与Spark的服务开启命令冲突 start-all.sh如果没有配置环境变量:首先需要进入
hadoop/sbin目录,然后执行上述命令即可(此情况下start-all.sh不会与Spark冲突)输入命令
jps,可以查看Hadoop集群是否正常开启:
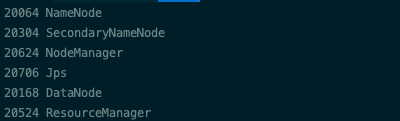
如果输出内容相比上图有缺失,则说明有服务没有正常开启。否则则说明Hadoop集群已经正常开启运行。
在浏览器输入localhost:9870可以访问hadoop文件系统: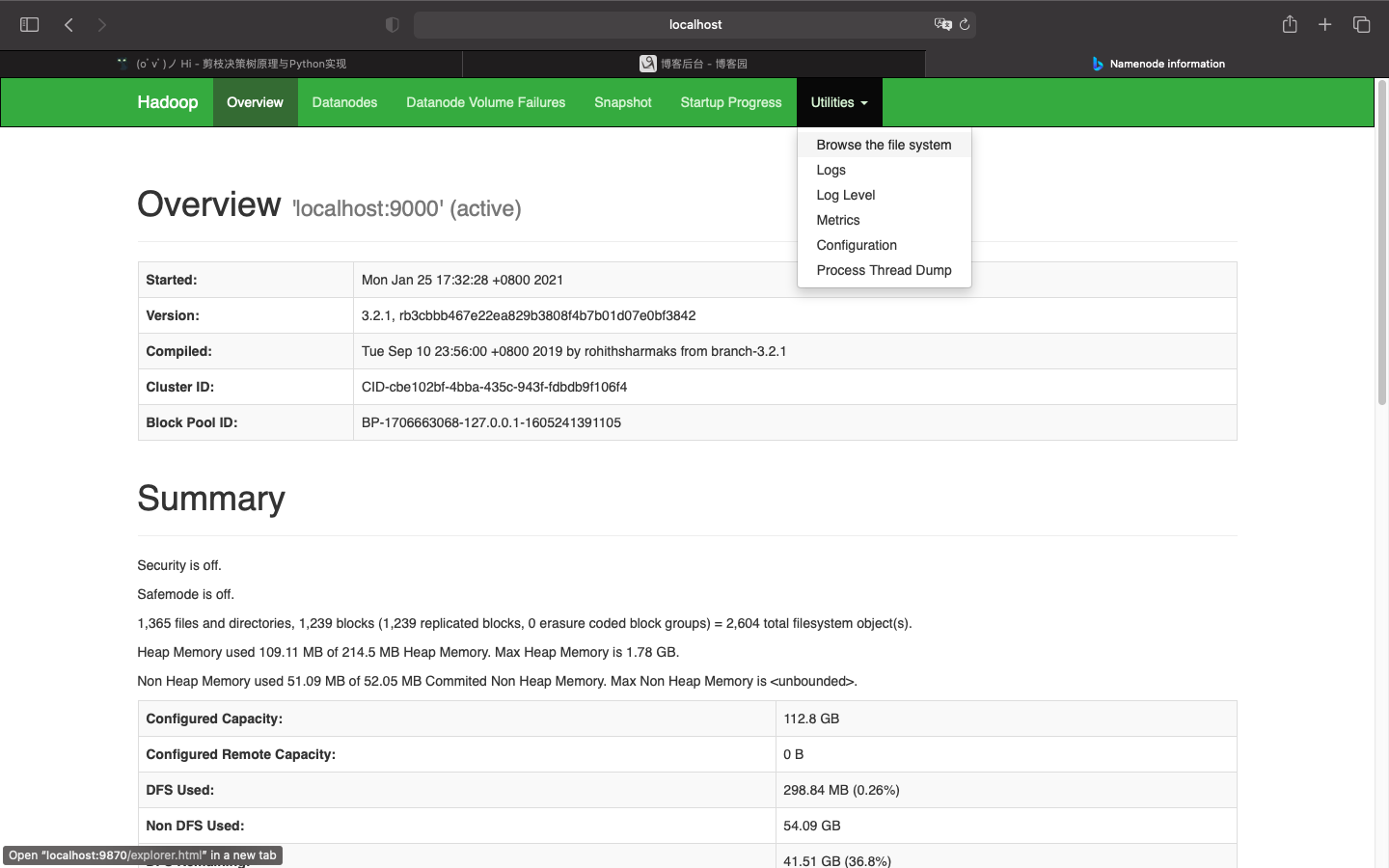
如果是Hadoop 2.X版本,则链接为http://localhost:50070/
在浏览器输入localhost:8088可以访问资源调度系统:
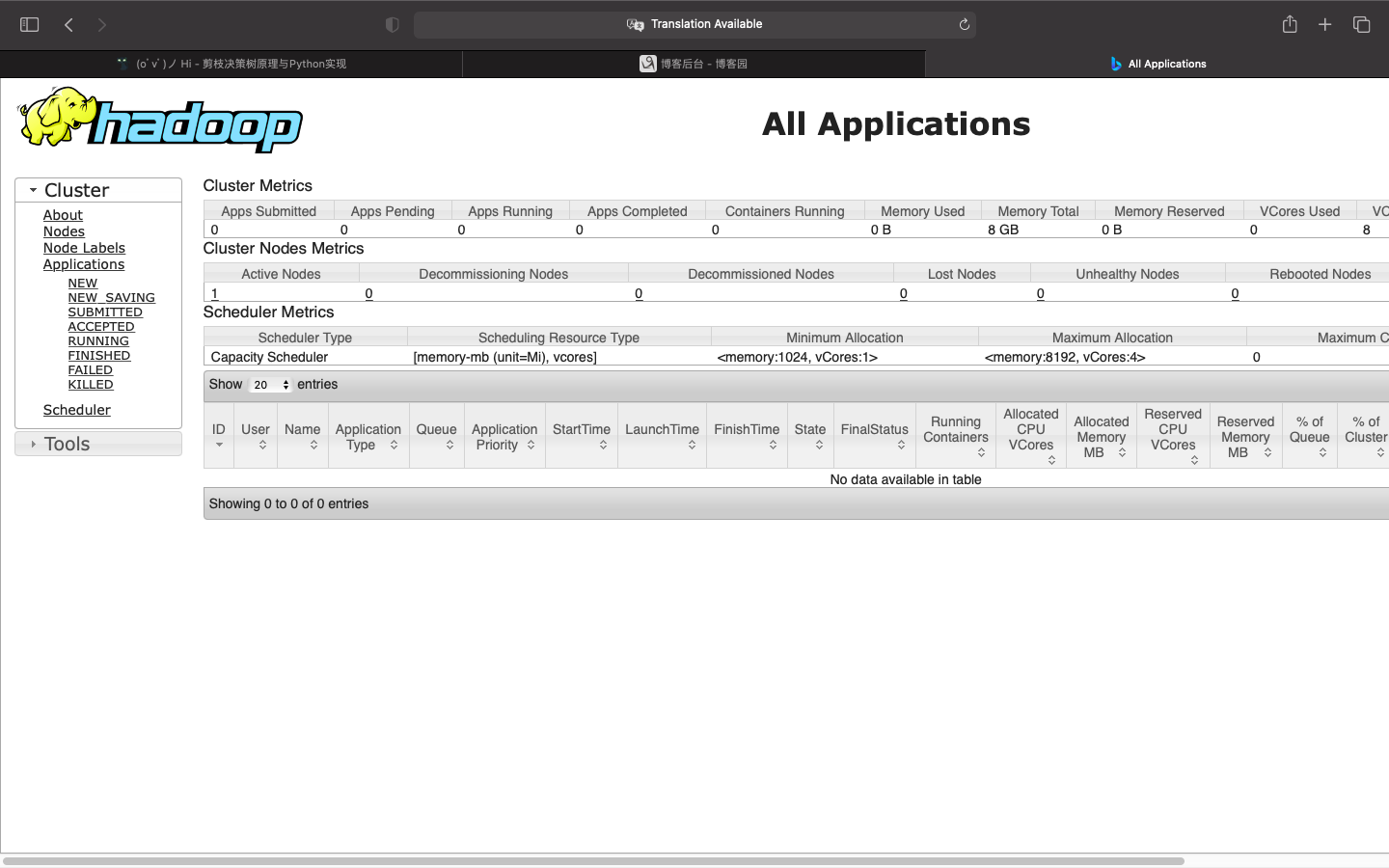
关闭Hadoop集群:
stop-all.sh本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!