本文为MSc Data Project 开发过程中出现的问题汇总
运行Spark时显示LOG目录没有更改权限
chown: changing ownership of ‘/data/opt/msc_big_data/spark-3.0.1-bin-hadoop2.7/logs’: Operation not permitted
由于使用的为实验室集群,MSc学生用户没有sudo权限,而默认的Spark Log目录在其它用户文件夹中,所以我们需要更改.bashrc文件,增加对自己Spark Log目录的定义。
在.bashrc文件中添加:
export SPARK_LOG_DIR=/home/[user dir]/spark_log
- 上述
[user dir]需要更改为自己具体的位置- 集群中不止是 Master 机器,所有 Worker 机器都需要更改
.bashrc
运行etl.py时出现OutOfMemoryError: Java heap space或者GC overhead limited
ETL, which stands for extract, transform and load.
上述问题均是由于 spark-submit 运行时driver-memory参数设置过小导致的,只需要在运行 spark-submit时添加 --driver-memory 10g参数便可,此处我设置参数大小为10g,视具体情况改变。运行命令示例:
spark-submit --driver-memory 10g etl.py运行etl.py时出现 Master 机器与 Worker 机器 Python 版本不同的问题
exception: python in worker has different version 3.6 than that in driver 3.7, pyspark cannot run with different minor versions. please check environment variables pyspark_python and pyspark_driver_python are correctly set.
同样,由于使用的为实验室集群,MSc 学生用户没有sudo权限,更改不了 Worker 机器的 Python 版本,于是我们只能曲线救国使用miniconda创建虚拟环境来更改 Worker 机器的 Python版本。
下载miniconda安装脚本
在 miniconda 官网下载页面中我们可以找到对应 Python 版本的安装脚本:
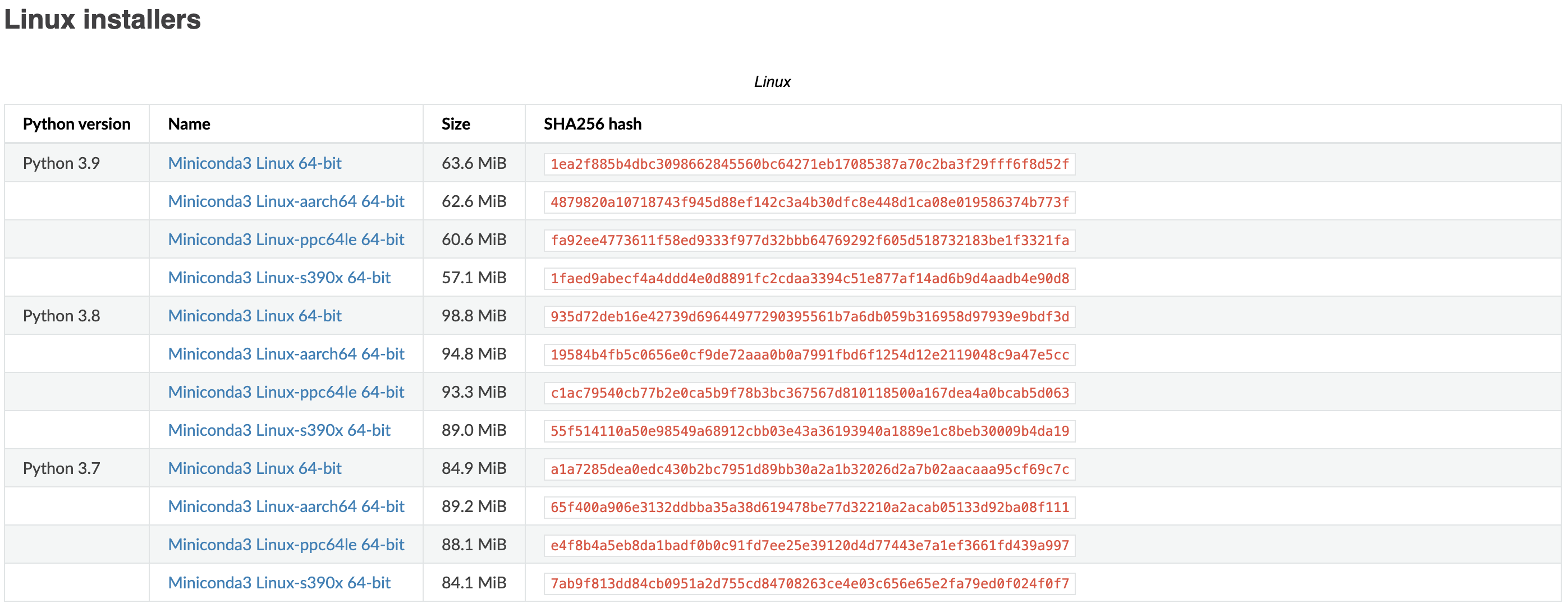
右键复制下载链接,在 Worker 机器中输入wget [下载链接]便可以获取安装脚本,运行命令示例:
wget https://repo.anaconda.com/miniconda/Miniconda3-py37_4.10.3-Linux-x86_64.sh安装miniconda
运行安装脚本,遵循提示安装:
bash Miniconda3-py37_4.10.3-Linux-x86_64.sh创建虚拟环境,设置为默认环境
创建虚拟环境:
conda create --name [your preferred name] python=3.7添加以下激活命令到.bashrc文件中:
activate [your preferred name]之后使其生效:
resource .bashrc运行Spark之后出现WebUI端口占用问题
ERROR ui.MasterWebUI: Failed to bind MasterWebUI
java.net.BindException: Failed to bind to /0.0.0.0:8096: Service 'MasterUI' failed after 16 retries (starting from 8080)!出现上述问题说明端口8080~8096都已经被占用,而此时我们没有sudo权限,更改不了Spark里面start-all.sh的内容,则需要更改spark-env.sh,在里面添加:
export SPARK_MASTER_WEBUI_PORT=13210 #set port no. to your preferred no.本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!