JZ23 链表中环入口的结点
描述
给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null。
思路
使用快慢指针,首先快慢指针相遇确定相遇点。相遇之后快指针不变(但是速度变为和慢指针相同,相当于也是一个慢指针),继续走,同时新建一个慢指针,从头节点继续走,这次两个指针相遇的地方就是环的入口了。
具体原理:
链表头到环入口长度为–a
环入口到相遇点长度为–b
相遇点到环入口长度为–c
则:相遇时
快指针路程=a+(b+c)k+b ,k>=1 其中b+c为环的长度,k为绕环的圈数(k>=1,即最少一圈,不能是0圈,不然和慢指针走的一样长,矛盾)。
慢指针路程=a+b
快指针走的路程是慢指针的两倍,所以:
(a+b)*2=a+(b+c)k+b
化简可得:
a=(k-1)(b+c)+c 这个式子的意思是: 链表头到环入口的距离=相遇点到环入口的距离+(k-1)圈环长度。其中k>=1,所以k-1>=0圈。所以两个指针分别从链表头和相遇点出发,最后一定相遇于环入口。

代码
class Solution {
public:
ListNode* EntryNodeOfLoop(ListNode* pHead)
{
ListNode *fast=pHead,*low=pHead;
while(fast&&fast->next){ //注意此处为 &&
fast = fast->next->next;
low = low->next;
if(fast == low)
break;
}
if(!fast||!fast->next)//无环, 注意此处为 ||
return NULL;
low = pHead;
while(low!=fast){
low = low->next; //注意两个都是一个next,a = (k-1)(b+c)+c
fast = fast->next;
}
return low;
}
};JZ6 从尾到头打印链表
描述
思路
有三种思路,第一就是利用栈先入后出的特性完成,第二就是存下来然后进行数组翻转。
第三是利用递归(类似后续遍历,先访问后输出)。
代码1
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head) {
vector<int> ret;
ListNode* p=head;
stack<int> stackList;
while(p){
stackList.push(p->val); //入栈
p = p->next;
}
while(!stackList.empty()){
ret.push_back(stackList.top()); //插入vector
stackList.pop();
}
return ret;
}
};代码2
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head) {
vector<int> value;
ListNode *p=NULL;
p=head;
while(p!=NULL){
value.push_back(p->val);
p=p->next;
}
//reverse(value.begin(),value.end()); //C++自带的翻转函数
int temp=0;
int i=0,j=value.size()-1;
while(i<j){
temp=value[i]; //也可以用swap函数,swap(value[i],value[j]);
value[i]=value[j];
value[j]=temp;
i++;
j--;
}
return value;
}
}; 代码3
class Solution {
public:
vector<int> value;
vector<int> printListFromTailToHead(ListNode* head) {
ListNode *p=NULL;
p=head;
if(p!=NULL){
if(p->next!=NULL){
printListFromTailToHead(p->next);
}
value.push_back(p->val);
}
return value;
}
};JZ24 反转链表
描述
给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。
要求:空间复杂度 O(1) ,时间复杂度 O(n)。
如当输入链表{1,2,3}时,
经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。
以上转换过程如下图所示:
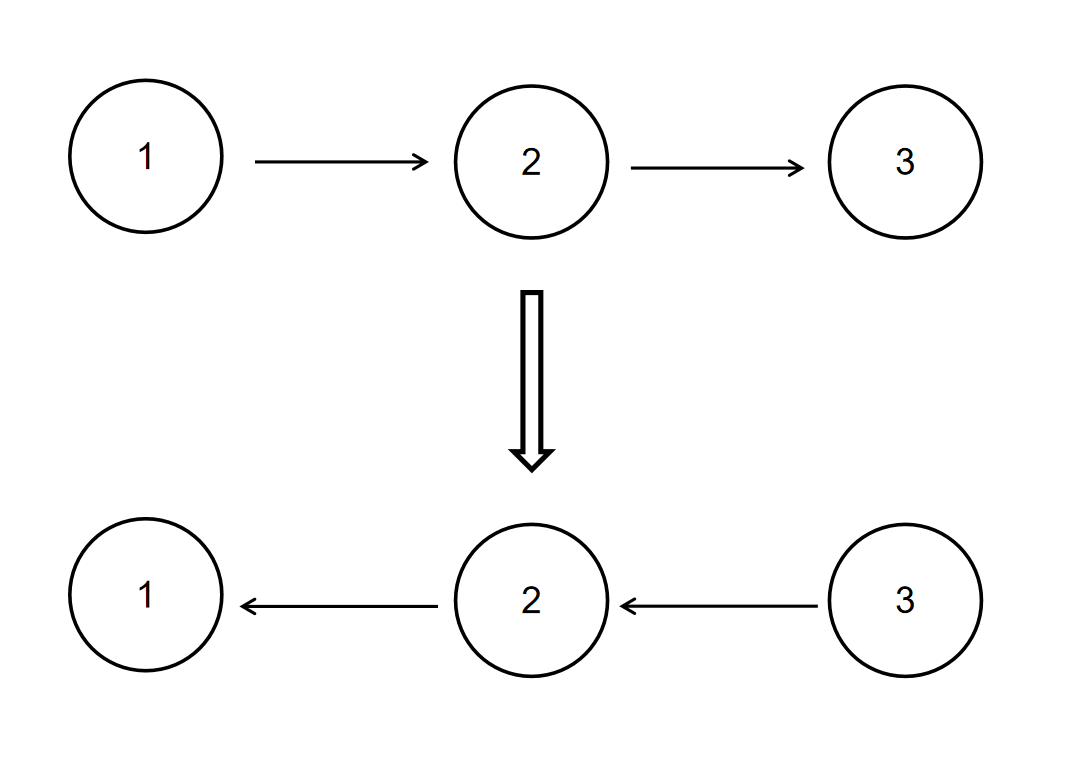
思路
思路很简单:1->2->3->4->5,遍历链表,把1的next置为None,2的next置为1,以此类推,5的next置为4。得到反转链表。需要考虑链表只有1个元素的情况。图中有具体的每步迭代的思路,最后输出pre而不是cur是因为最后一次迭代后cur已经指向None了,而pre是完整的反向链表。
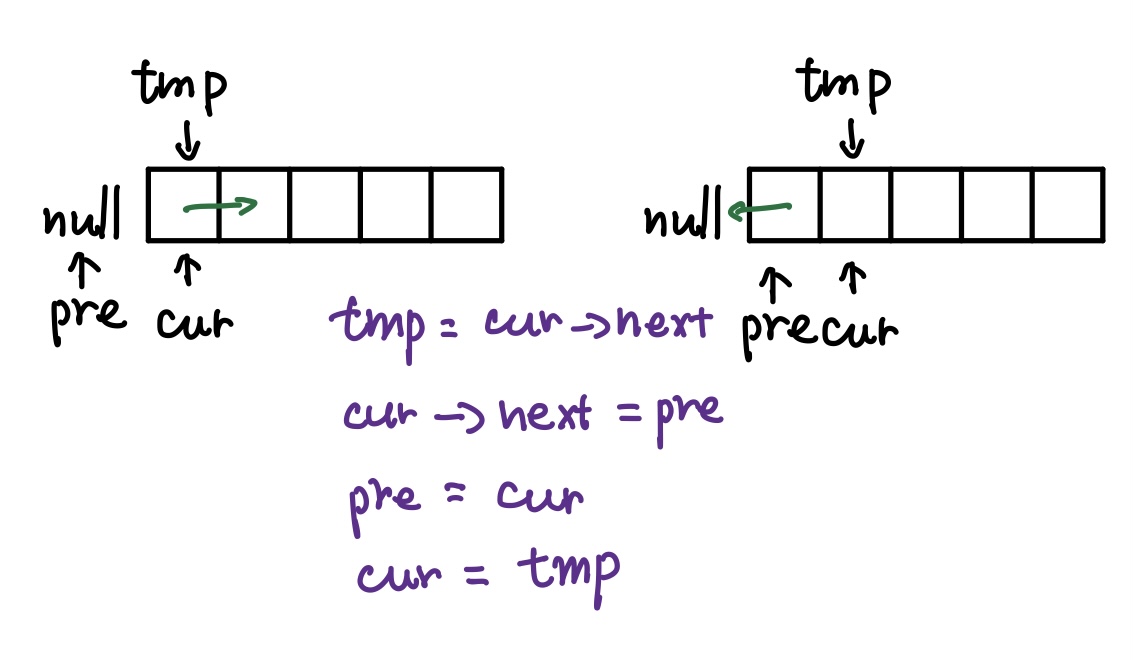
代码
class Solution {
public:
ListNode* ReverseList(ListNode* pHead) {
if(!pHead || !pHead->next){ //只需要判断head和head->next
return NULL;
}
ListNode* pre = nullptr;
ListNode* cur = pHead;
ListNode* temp;
while(cur){ //关键代码
temp = cur->next;
cur->next = pre;
pre = cur;
cur = temp;
}
return pre;
}
};JZ25 合并两个排序的链表
描述
输入两个递增的链表,单个链表的长度为n,合并这两个链表并使新链表中的节点仍然是递增排序的。
要求:空间复杂度 O(1),时间复杂度 O(n)
思路
两种方式,一种为递归,确定好哪个结点更小之后就直接对当前结点的next赋值,原先的next放入递归函数中,不怕丢失;
另一种为新建一个头结点和当前操作的结点,哪个更小就把哪个当成当前操作的结点(对刚开始排序的第一个结点需要特殊判断)。
代码1
public ListNode Merge(ListNode list1,ListNode list2) {
if(list1 == null){
return list2;
}
if(list2 == null){
return list1;
}
if(list1.val <= list2.val){
list1.next = Merge(list1.next, list2);
return list1;
}else{
list2.next = Merge(list1, list2.next);
return list2;
}
}代码2
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2) {
if (!pHead1) {
return pHead2;
}
if (!pHead2) { //只需要判断单个链表非空,不需要看全空的状态
return pHead1;
}
ListNode *head1 = pHead1, *head2 = pHead2;
ListNode *cur, *mergeHead = nullptr;
while(head1&&head2){
if (head1->val <= head2->val) {
if (!mergeHead) {
mergeHead = head1;
cur = head1;
} else {
cur->next = head1; //使用cur->next就不需要考虑断链什么的,是多开辟一条道路
cur = cur->next;
}
head1 = head1->next;
} else {
if (!mergeHead) {
mergeHead = head2;
cur = head2;
} else {
cur->next = head2;
cur = cur->next;
}
head2 = head2->next;
}
}
if (!head2) {
cur->next = head1;
}
if (!head1) {
cur->next = head2;
}
return mergeHead;
}
};JZ52 两个链表的第一个公共结点
描述
输入两个无环的单向链表,找出它们的第一个公共结点,如果没有公共节点则返回空。(注意因为传入数据是链表,所以错误测试数据的提示是用其他方式显示的,保证传入数据是正确的)
数据范围:n ≤ 1000
要求:空间复杂度 O(1),时间复杂度 O(n)
例如,输入{1,2,3},{4,5},{6,7}时,两个无环的单向链表的结构如下图所示:
可以看到它们的第一个公共结点的结点值为6,所以返回结点值为6的结点。
输入描述:
输入分为是3段,第一段是第一个链表的非公共部分,第二段是第二个链表的非公共部分,第三段是第一个链表和第二个链表的公共部分。 后台会将这3个参数组装为两个链表,并将这两个链表对应的头节点传入到函数FindFirstCommonNode里面,用户得到的输入只有pHead1和pHead2。
返回值描述:
返回传入的pHead1和pHead2的第一个公共结点,后台会打印以该节点为头节点的链表。

思路
找出2个链表的长度,然后让长的先走两个链表的长度差,然后再一起走(因为2个链表用公共的尾部)。
代码
class Solution {
public:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
ListNode *ret = NULL;
if (!pHead1||!pHead2) {
return ret;
}
int lenNode1 = 0, lenNode2 = 0;
ListNode *curP1 = pHead1, *curP2 = pHead2;
while (curP1) {
curP1 = curP1->next;
lenNode1++;
}
while (curP2) {
curP2 = curP2->next;
lenNode2++;
}
curP1 = pHead1;
curP2 = pHead2;
if ( lenNode1 > lenNode2) {
for (int i = 0; i < lenNode1-lenNode2; i++) {
curP1 = curP1->next;
}
} else if ( lenNode2 > lenNode1) {
for (int i = 0; i < lenNode2-lenNode1; i++) {
curP2 = curP2->next;
}
}
while ( curP1 && curP2) {
if ( curP1 == curP2) { //此处可以是地址也可以是值相同
ret = curP1;
break;
}
curP1 = curP1->next;
curP2 = curP2->next;
}
return ret;
}
};JZ22 链表中倒数最后k个结点
描述
输入一个长度为 n 的链表,返回该链表中倒数第k个节点。
如果该链表长度小于k,请返回一个长度为 0 的链表。
要求:空间复杂度 O(n),时间复杂度 O(n)
进阶:空间复杂度 O(1),时间复杂度 O(n)
例如输入{1,2,3,4,5},2时,对应的链表结构如下图所示:
其中蓝色部分为该链表的最后2个结点,所以返回倒数第2个结点(也即结点值为4的结点)即可,系统会打印后面所有的节点来比较。

思路
双指针,一根指针先走k步(边走边判断是否为空,因为链表长可能小于k),最后两根指针一起走,前面那根指针为空时后面的指针所指即为所求。
代码
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead ListNode类
* @param k int整型
* @return ListNode类
*/
ListNode* FindKthToTail(ListNode* pHead, int k) {
// write code here
ListNode *cur = pHead, *curSlow = pHead, *ret = NULL;
while (cur && k) {
cur = cur->next;
k--;
}
if ( k ) { //链表没有K怎么长的情况
return ret;
}
while ( cur ) { //慢指针出发
cur = cur->next;
curSlow = curSlow->next;
}
return curSlow;
}
};JZ18 删除链表中的结点
描述
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。返回删除后的链表的头节点。
1.此题对比原题有改动
2.题目保证链表中节点的值互不相同
3.该题只会输出返回的链表和结果做对比,所以若使用 C 或 C++ 语言,你不需要 free 或 delete 被删除的节点
数据范围:
0<=链表节点值<=10000
0<=链表长度<=10000
思路
一个pre指针一个cur指针,记录好每个结点的pre用来pre->next = cur->next,特殊条件只需要考虑head就是当前值就行,如果链表中没有相等的值也是直接返回head。
代码
*/
class Solution {
public:
ListNode* deleteNode(ListNode* head, int val) {
// write code here
ListNode *ret = head;
if (!head) //可能为空链表,这时候直接返回空
return head;
if (head->val == val) {
return head->next;
}
ListNode *cur = head->next, *pre = head;
while ( cur ) {
if ( cur->val == val ) {
pre->next = cur->next;
break;
}
pre = cur;
cur = cur->next;
}
return ret;
}
};JZ76 删除链表中重复的结点
描述
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表 1->2->3->3->4->4->5 处理后为 1->2->5
数据范围:0≤n≤1000 ,链表中的值满足 1≤val≤1000
进阶:空间复杂度 O(n),时间复杂度 O(n)
例如输入{1,2,3,3,4,4,5}时,对应的输出为{1,2,5},对应的输入输出链表如下图所示:
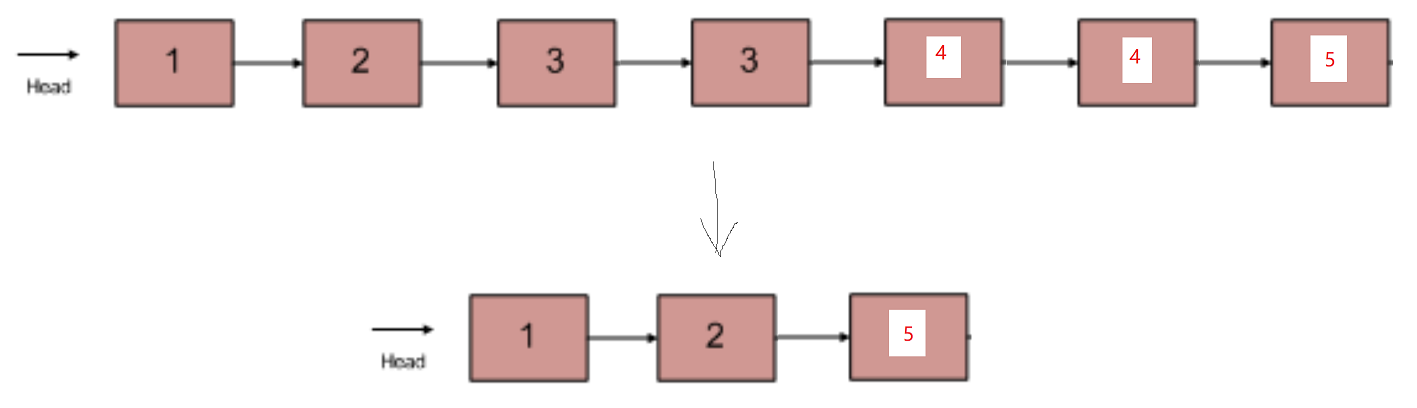
思路
非递归的代码:
- 首先添加一个pre头节点,以方便碰到第一个,第二个节点就相同的情况
- 设置 pre ,last 指针, pre指针指向当前确定不重复的那个节点,而last指针相当于工作指针,一直往后面搜索。
代码
class Solution {
public:
ListNode* deleteDuplication(ListNode* pHead) {
if ( !pHead || !pHead->next) {
return pHead;
}
ListNode *retPre = new ListNode(0);
retPre->next = pHead;
ListNode *pre = retPre, *last = pHead;
while ( last ){
if ( last->next && last->next->val == last->val ) {
while ( last->next && last->val == last->next->val) { //首先要判断last->next非空,不然会段错误
last = last->next;
}
pre->next = last->next;
last = last->next;
} else {
pre = pre->next;
last = last->next;
}
}
return retPre->next;
}
};本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!