如何把列表中的数字转化为字符串用匿名函数
用列表表达式:
[str(i) for i in fList]
python找包的顺序
1.先从内存空间中查找
2.再从内置模块中查找
3.最后去sys.path查找(类似于我们前面学习的环境变量)
如果上述三个地方都找不到 那么直接报错!!!
绝对导入与相对导入
相当于绝对路径和相对路径
python 可变对象 不可变对象
| 可变对象 | 不可变对象 |
|---|---|
| 对象的内容是可变的,例如 list | 其内容不可变,例如常量1 |
不可变对象
由于 Python 中的变量存放的是对象引用,所以对于不可变对象而言,尽管对象本身不可变,但变量的对象引用是可变的。运用这样的机制,有时候会让人产生糊涂,似乎可变对象变化了。如下面的代码:
i = 73
i += 2
从上面得知,不可变的对象的特征没有变,依然是不可变对象,变的只是创建了新对象,改变了变量的对象引用。
可变对象
其对象的内容是可以变化的。当对象的内容发生变化时,变量的对象引用是不会变化的。如下面的例子。
m=[5,9]
m+=[6] 
- 不可变对象:对象不可变;对象引用可变
- 可变对象:对象可变
列表推导式
规范
variable = [out_exp for out_exp in input_list if out_exp == 2]这里是另外一个简明例子:
multiples = [i for i in range(30) if i % 3 is 0]
print(multiples)
# Output: [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]当你需要使用 for 循环来生成一个新列表。举个例子,你通常会这样做:
squared = []
for x in range(10):
squared.append(x**2)你可以使用列表推导式来简化它,就像这样:
squared = [x**2 for x in range(10)]字典推导式
例子:
mcase = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
mcase_frequency = {
k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0)
for k in mcase.keys()
}
# mcase_frequency == {'a': 17, 'z': 3, 'b': 34}在上面的例子中我们把同一个字母但不同大小写的值合并起来了。
快速对换一个字典的键和值:
{v: k for k, v in some_dict.items()}集合推导式
它们跟列表推导式也是类似的。 唯一的区别在于它们使用大括号{}:
squared = {x**2 for x in [1, 1, 2]}
print(squared)
# Output: {1, 4}Python深浅拷贝
深拷贝和浅拷贝是针对可变对象:list、dict 和 set集合
python 中的深拷贝和浅拷贝使用
copy 模块
浅拷贝
浅拷贝使用copy.copy()
import copy
a = [1, "hello", [2, 3], {"key": "123"}]
b = copy.copy(a)- 浅拷贝会创建一个新的容器对象(compound object)
- 对于对象中的元素,浅拷贝就只会使用原始元素的引用(内存地址)
常见的浅拷贝操作有:
- 使用切片操作[:]
- 使用工厂函数(如list/dict/set)
- copy模块的copy()方法
深拷贝
深拷贝使用copy.deepcopy()
import copy
a = [1, "hello", [2, 3], {"key": "123"}]
b = copy.deepcopy(a)- 深拷贝和浅拷贝一样,都会创建一个新的容器对象(compound object)
- 和浅拷贝的不同点在于,深拷贝对于对象中的元素,深拷贝都会重新生成一个新的对象
Python内存管理
变量与对象
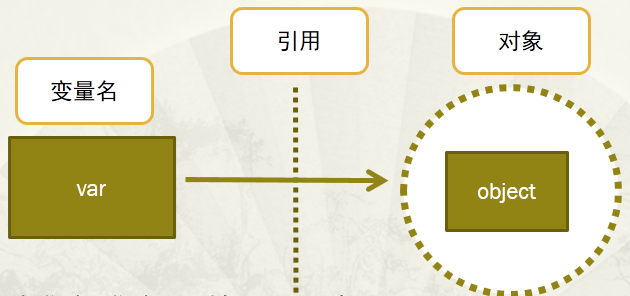
变量,通过变量指针引用对象
- 变量指针指向具体对象的内存空间,取对象的值。
对象,类型已知,每个对象都包含一个头部信息(头部信息:类型标识符和引用计数器)
注意:
变量名没有类型,类型属于对象(因为变量引用对象,所以类型随对象),变量引用什么类型的对象,变量就是什么类型的。
1、Python缓存了整数和短字符串,因此每个对象在内存中只存有一份,引用所指对象就是相同的,即使使用赋值语句,也只是创造新的引用,而不是对象本身;
2、Python没有缓存长字符串、列表及其他对象,可以由多个相同的对象,可以使用赋值语句创建出新的对象。
引用计数
在Python中,每个对象都有指向该对象的引用总数—引用计数
查看对象的引用计数:sys.getrefcount()
注意:
当使用某个引用作为参数,传递给getrefcount()时,参数实际上创建了一个临时的引用。因此,getrefcount()所得到的结果,会比期望的多1。
In [2]: import sys
In [3]: a=[1,2,3]
In [4]: getrefcount(a)
Out[4]: 2引用计数增加
- 对象被创建
- 另外的别人被创建
- 作为容器对象的一个元素
- 被作为参数传递给函数:foo(x)
引用计数减少
- 对象的别名被显式的销毁
- 对象的一个别名被赋值给其他对象
- 对象从一个窗口对象中移除,或,窗口对象本身被销毁
- 一个本地引用离开了它的作用域,比如上面的foo(x)函数结束时,x指向的对象引用减1
垃圾回收
当Python中的对象越来越多,占据越来越大的内存,启动垃圾回收(garbage collection),将没用的对象清除。
当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾。
比如某个新建对象,被分配给某个引用,对象的引用计数变为1。如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。
In [74]: a=[321,123]
In [75]: del a注意
- 垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率;
- Python只会在特定条件下,自动启动垃圾回收(垃圾对象少就没必要回收);
- 当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
分代回收
Python将所有的对象分为0,1,2三代。
所有的新建对象都是0代对象。当某一代对象经历过垃圾回收,依然存活,那么它就被归入下一代对象。
垃圾回收启动时,一定会扫描所有的0代对象。如果0代经过一定次数垃圾回收,那么就启动对0代和1代的扫描清理。
当1代也经历了一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描。
内存池机制
Python中有分为大内存和小内存:(256K为界限分大小内存)
- 大内存使用malloc进行分配
- 小内存使用内存池进行分配
Python的内存池(金字塔)
- 第3层:最上层,用户对Python对象的直接操作
- 第1层和第2层:内存池,有Python的接口函数
PyMem_Malloc实现—–若请求分配的内存在1~256字节之间就使用内存池管理系统进行分配,调用malloc函数分配内存,但是每次只会分配一块大小为256K的大块内存,不会调用free函数释放内存,将该内存块留在内存池中以便下次使用。 - 第0层:大内存—–若请求分配的内存大于256K,malloc函数分配内存,free函数释放内存。
- 第-1,-2层:操作系统进行操作
classmethod & staticmethod
@classmethod修饰符:
对应的函数不需要实例化,不需要self参数,但第一个参数需要是表示自身类的cls参数,可以来调用类的属性,类的方法,实例化对象等。
它的作用就是有点像静态类,比静态类不一样的就是它可以传进来一个当前类作为第一个参数。以后重构类的时候不必要修改构造函数,只需要额外添加你要处理的函数,然后使用装饰符 @classmethod 就可以了。
直接类名.方法名()来调用。这有利于组织代码,把某些应该属于某个类的函数给放到那个类里去,同时有利于命名空间的整洁。
@classmethod的作用实际是可以在class内实例化class,一般使用在有工厂模式要求时。作用就是比如输入的数据需要清洗一遍再实例化,可以把清洗函数定义在class内部并加上@classmethod装饰器已达到减少代码的目的。总结起来就是:@classmethod可以用来为一个类创建一些预处理的实例。
例如:
string_date=’2020-1-1’
year,month,day=map(int,string_date.split(‘-‘))
s=Data_test(year,month,day)
把这个字符串处理的函数放到 Date_test 类当中:
class Data_test2(object):
day=0
month=0
year=0
def __init__(self,year=0,month=0,day=0):
self.day=day
self.month=month
self.year=year
@classmethod
def get_date(cls,data_as_string):
#这里第一个参数是cls, 表示调用当前的类名
year,month,day=map(int,data_as_string.split('-'))
date1=cls(year,month,day) #返回的是一个初始化后的类
return date1
def out_date(self):
print("year :",self.year)
print("month :",self.month)
print("day :",self.day)
调用方法变为:
r=Data_test2.get_date(“2020-1-1”)
r.out_date()
等于先调用get_date()对字符串进行出来,然后才使用Data_test的构造函数初始化。
这样的好处就是你以后重构类的时候不必要修改构造函数,只需要额外添加你要处理的函数,然后使用装饰符 @classmethod 就可以了。
1)Factory methods(工厂方法模式)
工厂方法模式即用户只需通过固定的接口获得一个对象的实例,降低了维护的复杂性。
class Pizza(object):
def __init__(self, ingredients): #ingredient:原料种类
self.ingredients = ingredients
@classmethod
def from_fridge(cls, fridge):
return cls(fridge.get_cheese() + fridge.get_vegetables())这里的classmethod from_fridge(cls, fridge)返回Pizza对象,这个Pizza是冰箱里的Pizza。假如我们用静态方法来写的话,还需要在函数中hardcode the Pizza class name,继承Pizza。
(2)调用static method
class Pizza(object):
def __init__(self, radius, height):
self.radius = radius
self.height = height
@staticmethod
def compute_area(radius):
return math.pi * (radius ** 2)
@classmethod
def compute_volume(cls, height, radius):
return height * cls.compute_area(radius) #调用@staticmethod方法
def get_volume(self):
return self.compute_volume(self.height, self.radius) staticmethod
和class method很相似的是staticmethod,但它不需要表示自身对象的self和自身类的cls参数,就跟使用函数一样。(python没有重载)
staticmethod相当于一个定义在类里面的函数,所以如果一个方法既不跟实例相关也不跟特定的类相关,推荐将其定义为一个staticmethod,这样不仅使代码一目了然,而且似的利于维护代码。
子类调用方法隐形传入的参数为该对象所对应的类,调用过程中动态生成了对应的类的类变量。
理解classicmethod和staticmethod类是一种数据结构,可以创建对象。当调用类的时候就创建了一个类的实例对象。一旦对象被创建,python 就会检查是否实现了init()方法。如果init()已经被实现,那么它将被调用,实例对象作为第一个参数(self)被传递进去。
优点:
分解字符串操作可以重复使用,而我们只需要传入参数一次;
OOP;
cos是类本身,而不是类的实例,当我们将Date作为父类时,其子类也会拥有from_string方法
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!